
This is a technical appendix to the Melodjinn demo in The AI Sound House. I’m writing this as working notes, hoping they’re useful to whoever pushes the idea further. The code is available on GitHub.
The problem
On the surface, the premise of the project is simple: apply DeepMind’s unsupervised Genie framework for building world models to music. After all, music is a kind of world with its own dynamics and actions. What are those actions and who’s taking them is part of this investigation. In the low-level view, actions could be notes played by a musician. In the higher-level one, they’re the structural decisions a producer or DJ makes: when to drop, when to build, changes in tempo, etc.
But this wasn’t the actual starting point.
I love music. I consume it constantly and selectively. But mainstream interfaces aren’t built for the kind of daily navigation I want. Spotify’s recommendations often feel repetitive, and there’s no way to steer them towards what I “need” at any given time. Also, they make it hard to discover music as a coherent whole, like through a new album or mix. I learned to DJ, which does scratch that itch: every session is different, making it easy to stumble onto new territory, and you build up a coherent mood. But it’s a full-time activity.
There’s a missing middle ground that no tool (or instrument for that matter) quite fills. The closest approximation I found is SoundCloud: not for its social features, but for its collection of mixes and its mobile player. Scrolling a mix’s waveform with your finger gives a faint vibration as you move and resumes playback instantly when you release. It’s tactile, like feeling your way along a surface until the texture lines up with your mood. It feels like introspection.
But the underlying axis is fixed: it’s the artist’s timeline. Your distribution of good continuations is different, and it’s multimodal: many directions could work for you. What I really want is a map: a way to efficiently navigate music with temporal coherence, but along paths aligned with my own tastes and state.
Text-to-music
AI music generation looks like the natural step forward, where the main interface today is text. Two issues stand out. First, most models can’t generate in real time, so you lose the continuous thread that makes mixes compelling. The second is that musical needs are hard to introspect and formulate in text: at least for me, it’s closer to adjusting a dial.
Which brings me to the idea: generation that can be steered as it unfolds, in directions that feel intuitive to the user and remain stable across sessions. Lyria’s real-time prompting shows one way to do this via text or audio cues, but it still relies on the user’s ability to introspect via text. An alternative is to discover the structure of musical transitions directly from audio, in the same way that Genie discovers actions by modeling video dynamics. And then use those actions to let the user guide generation in real time. That’s the premise behind Melodjinn.
To recap, here’s what I want out of a v1:
☐ Real-time generation you can steer as it plays
☐ Stable action space across sessions, so you can learn the UI
☐ Actions that make sense to humans (builds, energy, mood, pitch)
☐ Personalized so you can navigate toward what you need fast
☐ Actual bangers
The architecture
For a deeper, practical dive into the Genie architecture, I recommend TinyWorlds and GenieRedux.
In short, Melodjinn is composed of two models trained jointly: the Latent Action Model (LAM) and the Dynamics model. The LAM learns to discover discrete action tokens that capture transitions in audio. It first splits the raw waveform into non-overlapping patches, linearly projects each patch into an embedding, and processes the sequence with a transformer encoder. The encoder outputs are then temporally shifted: the encoding at position $t+1$ is quantized with a VQ-VAE to produce an action token for position $t$. The LAM decoder then receives the patch embedding at position $t$ plus this quantized action, and must reconstruct the patch at position $t+1$ using causal attention. The action acts as a peek into the future: to minimize reconstruction loss, the decoder learns to exploit it, which in turn pressures the VQ codebook to encode meaningful and shared audio transitions.
The Dynamics model is an autoregressive transformer that predicts audio in EnCodec token space. EnCodec is a neural audio codec that compresses audio into discrete tokens across multiple codebooks. At each timestep, the dynamics model flattens these codebooks into a sequence and adds a codebook index embedding to help distinguish codebooks. The action token from the LAM is replicated across all codebooks and added to each audio token embedding. A single unembedding matrix is shared across all codebooks for simplicity. The model then predicts the next audio tokens.
The total loss is a sum of an input-space MSE loss on the reconstructed LAM waveform, the LAM VQ-VAE loss, and the Dynamics cross entropy next token prediction.
At inference, the dynamics model generates autoregressively from a seed, and you can select which action to apply at each step for real-time interactive control.
Toy world
I began with a toy setting to quickly expose coarse problems. The goal was simple: create the smallest environment where the LAM should discover a handful of discrete transitions, and the Dynamics model should use them to reconstruct the signal. A synthetic drum dataset works well for this: a few distinct hits placed randomly. In the ideal case, the model needs $N+1$ actions for $N$ drum types plus a NOOP.
To iterate quickly, I adapted the GenieRedux codebase. It’s built for video, but the mapping to audio is straightforward enough: raise the temporal resolution from 16 Hz to 24 kHz, treat EnCodec’s hop size (320 samples) as the temporal patch size, use the codebook dimension as a stand-in for the spatial x-axis, and collapse the y-axis to 1. This is not the right long-term architecture but it’s sufficient for a sanity check.
Metrics were not especially helpful early on, so I inspected the system directly: original waveform, LAM actions, and Dynamics generation using those actions.
With a single drum sound, everything worked immediately. With multiple drums, however, most runs produced what looked like saturated noise. Only a small minority worked.
After some painful digging I realized that the issue had nothing to do with model learning. In my debug plots, I was conditioning the Dynamics model on the ground-truth action sequence rather than the LAM-derived one. With two drum types, the VQ codebook had a 50% chance to align its learned action indices with the ground truth, so some runs “worked.” With more types, accidental alignment became extremely unlikely. What I interpreted as “noise” was just the model repeating one drum hit instead of NOOP. Obvious in hindsight. With that sorted, here are the training dynamics:
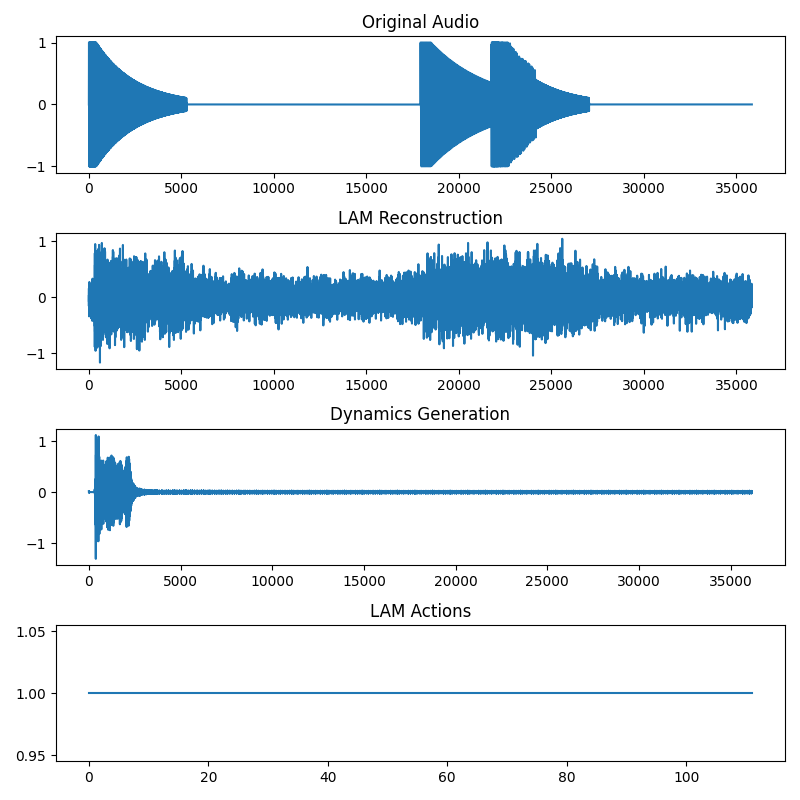
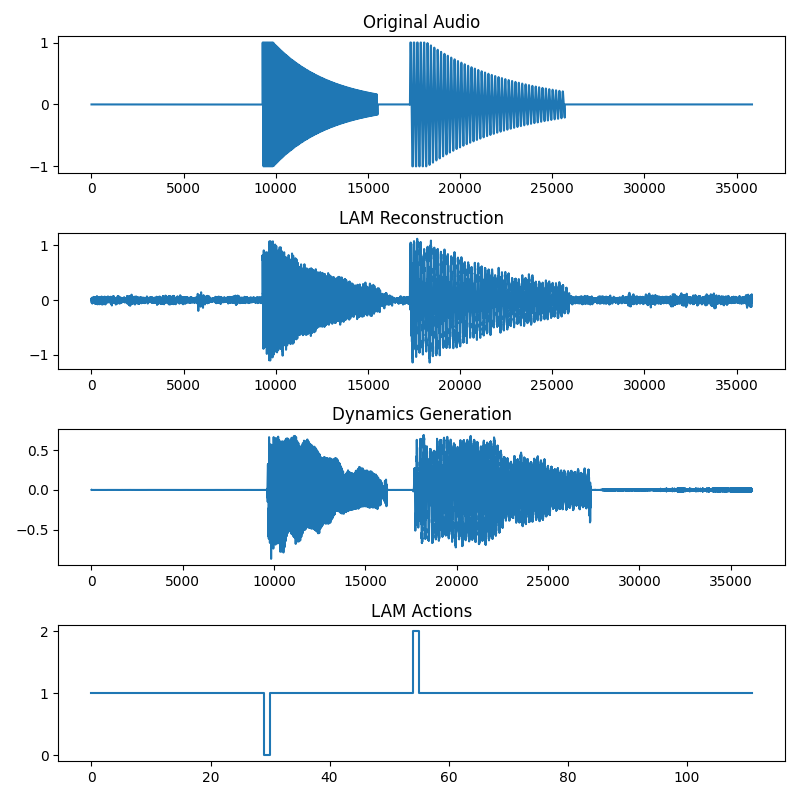
In the Genie paper, they mention better results when the LAM reconstructs in input space (raw pixels) because tokenizers introduce artifacts. I wanted to stress-test this design choice, so I removed the LAM decoder and let the Dynamics loss backpropagate into the LAM encoder and VQ directly. This did produce good reconstructions from the Dynamics model, but the latent actions became very noisy: the LAM started overfitting to tiny EnCodec artifacts even when these differences were perceptually irrelevant. I reverted to raw waveform reconstruction. As I understand it, this mirrors Genie’s conclusion but for a different reason: they avoid tokens to prevent input smearing and loss of control, whereas I avoid them to preserve interpretability and user experience.
Another instability showed up during longer runs. The LAM occasionally “flipped” which code represented which transition during training, causing spikes in the Dynamics loss. Freezing the LAM after its early convergence fixed it. You could also train the LAM separately beforehand. I also noticed that in this toy setting, choosing drum samples with clearly distinct onsets helped. Otherwise the model assigned the same action to different hits. Most timesteps (silence and decay) are easy to predict from context and dominate the loss, only the onset truly requires an action.
With these adjustments, the toy setup behaved as expected. The LAM discovered a small, stable set of actions, and the Dynamics model reliably reconstructs the audio conditioned on them.
☑ Stable action space across sessions
☐ Actions that make sense to humans (builds, energy, mood, pitch)
☐ Personalized so you can navigate toward what you need fast
☐ Actual bangers
You can try it below, the demo runs EnCodec and the trained dynamics model in your browser via ONNX Runtime. By default it injects the discovered NOOP action; press keys 1, 2, or 3 to inject the discovered drum hits:
Real music
My first attempt used the Maestro dataset: around 200 hours of clean piano recordings. I trained a few scaled-up GenieRedux variants for a couple of days. The dynamics model produced vaguely musical output, but the LAM showed no stable or interpretable actions.
At that point I realized I needed a stronger initialization for the models. Otherwise, all my compute would go into relearning basic acoustics.
So I started fresh, this time on top of HuggingFace’s MusicGen implementation. The plan was: (1) fine-tune the Dynamics model quickly to get reasonable musical output on Maestro, and then (2) integrate the LAM. Step (1) worked exactly as hoped: MusicGen Small adapted in about an hour and produced plausible piano snippets.
But once I attached the LAM, everything broke. Even the toy drum world stopped working. A few examples of what went wrong:
Classifier-Free Guidance: MusicGen enables CFG by default at generation time. This produces two forward passes: one conditional, one unconditional. Since I wasn’t using text prompts, I didn’t bother overriding the conditional method. So, while the unconditional branch had actions injected thanks to my patch, the conditional branch did not. Their interpolation produced garbage audio because the Dynamics model was OOD without actions.
Sequence alignment: MusicGen inserts a start token. LAM operates directly on waveform patches. This introduced a consistent one-step shift between action positions and audio positions.
Action usage: I suspect that MusicGen is strong enough that, without masking timesteps, teacher forcing overwhelms the contribution of the action token. Masking was necessary to force the model to pay attention to actions, which TinyWorlds also notes.
After fixing these, I ran into a different obstacle: I didn’t have good intuitions for what “action structure” in classical music should look like. Techno is much better suited. I listen to it constantly, and its transitions are easier to reason about (drops, beats, etc). So I used a different dataset, Jamendo MaxCaps, filtered for techno (~700h) and trained again. Still no convincing action structure. Either training time was insufficient, or some HF-internal assumption was still interfering. And the code was getting bloated with patches and workarounds.
So I restarted the project a final time, from scratch, with zero external dependencies, and with the target architecture.
That rewrite paid off: a 400k-parameter version reproduced the toy drum world perfectly, and a 200M-parameter model finally began showing traction on Jamendo techno after a day of training.
The simplest validation was to take a real techno clip, extract its actions with the LAM, and ask the Dynamics model to generate a new sample conditioned on those actions. The outputs weren’t identical, but they shared structure. The model was following a direction instructed by the actions rather than copying the waveform, which was the behavior I was after!
Still, one pattern stood out. In v0.1, the LAM learned fine-grained transitions: micro-events around onsets, amplitude changes, local texture. These are technically valid transitions, but they’re not the level of abstraction I want for interactive music generation. Another related issue is that action sequences are dense. A human would need an action-prior model to drive the system when not interacting, and to hand control back when they intervene.
☑ Real-time generation you can steer as it plays
☑ Stable action space across sessions, so you can learn the UI
◐ Actions that make sense to humans
↳ v0.1 captures coherent transitions, but actions are too dense to be usable
☐ Personalized so you can navigate toward what you need fast
↳ not addressed yet
☐ Actual bangers
↳ need to scale up data and model
Towards v1
The core mechanism works on small setups, but scaling it to music people actually listen to and controls people actually want requires a lot more work. Here are a few directions that seem promising to me for building v1.
Scaling
Larger models trained longer on broader datasets are an obvious next step. The small models already show the right qualitative behaviors, and more capacity will improve musical quality. But scaling alone won’t solve the abstraction problem.
Temporal granularity
With the current short patches, the loss provides essentially no incentive for the LAM to encode abstract transitions into the actions. Larger patches would push the model to compress information at a coarser temporal scale. The longer-term goal is a hierarchy of actions, with both fine and coarse transitions available for control.
Action priors
If action sequences are dense like in my experiments, the system needs an agent to choose actions when the user isn’t interacting. In video games, a NOOP is desirable: you’re not trying to watch the game play itself. In music, listeners may actually want the system to keep evolving while they step back. A policy in action space can provide that continuity, with user inputs overriding it when needed.
Representations
The LAM is sensitive to the space it reconstructs in. Input-space reconstruction overemphasizes loudness and onsets while token-space reconstruction overfits to EnCodec artifacts. A better target space is likely needed: normalizing waveform patches, introducing a perceptual embedding, or using JEPA-style objectives that avoid reconstructing raw input. The goal is to remove low-level variance as an easy path to minimizing the loss, so that actions have to encode something closer to meaningful transitions.
Personalization
Different listeners care about different types of transitions, so a single action space may not be enough. A system that can adapt that space to your taste through something like RLHF would be great.